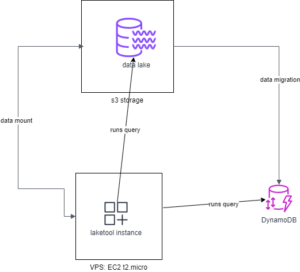
Here is summary of AWS services created for this experiment:
Experiment In this experiment we query data of 15474 files of League of Legends matches (average size of file is 21 KB) in both setups. The match file is quite nested JSON with a lot of properties. The structure of these files can be found in Riot (developer of League of Legends) API documentation.
We wanted to know for each match what was the total amount of damage inflicted by the first player during the game. JSON path to this data is as follows: “$.info.participants[0].totalDamageDealt”
Results Query in Laketool running on EC2 took 49.218s to retrieve full data. On the side of the DynamoDB query was executing for 7 min 47.703s which is almost 10 times slower but then it fails with error:
SELECT failed. ProvisionedThroughputExceededException. H2UR3BJP0C3O0UCK8RADAU94GVVV4KQNSO5AEMVJF66Q9ASUAAJG. The level of configured provisioned throughput for the table was exceeded. Consider increasing your provisioning level with the UpdateTable API. Terminated
Which suggests that for this amount of data, DynamoDB’s data throughput is too low (in base free version) and it can’t execute the query, returning the full data.
Conclusions Based on the test performed, it can be seen that Laketool running under the conditions of a weak free VM instance on the AWS platform, performs much better at the task of extracting data from JSON files than DynamoDB in the free version. Especially because Laketool doesn’t require the costly (in terms of time) and problematic process of migrating data from a file store to a database like DynamoDB does, but instead can run on uploaded files right away. Without the need for actually any configuration, other than pointing to the path of the data lake.
Indroduction In the ever-evolving landscape of data management, the quest for optimal performance is relentless. Today we want to compare our latest development: Laketool – software for quick data retrieval from JSON data lakes with AI model training capabilities versus popular Amazon Web Service NoSQL database – DynamoDB.
DynamoBD allows storing JSON objects into attributes of tables and performing various operations on these objects such as filtering, updating while retaining nested attributes within these objects. Of course, Laketool using its simple custom query language can also extract any nested data from JSON objects and has extensive capabilities in processing it.
We wanted to present a simple scenario to compare the performance of these systems, in which we extract some data from a rather large JSON dataset, operating directly on files stored in S3.
AWS setup and data migration To achieve this, we loaded a sample batch of data from our data lake, (data sourced from the popular game League of Legends),into the free-tier AWS S3 storage. Next, we spun up a basic Elastic Compute Cloud (EC2) virtual machine instance, creating a data mount to the previously created S3 file storage.
On the EC2 instance we installed the Laketool instance, which with access to the JSON files facilitated by S3 data mount, the system was ready to operate, querying and interacting with JSON files seamlessly.
On the side of DynamoDB we use a tool provided by AWS to migrate JSON files stored on S3 to DynamoDB as entries in the database table. For this purpose we needed to transform the original data, for DynamoDB to know types of each property (“payload” of files of unchanged) before running migration from the AWS control panel. For this purpose we wrote a custom script that was runned on EC2 with access to s3 to process all JSON files in the. lake It is also worth mentioning at this point that the process of migrating a mere 15474 files from s3 to DynamoDB took as long as 9 hours 20 minutes. Probably due to the low data throughput of DynamoDB.
Here is summary of AWS services created for this experiment:
Experiment In this experiment we query data of 15474 files of League of Legends matches (average size of file is 21 KB) in both setups. The match file is quite nested JSON with a lot of properties. The structure of these files can be found in Riot (developer of League of Legends) API documentation.
We wanted to know for each match what was the total amount of damage inflicted by the first player during the game. JSON path to this data is as follows: “$.info.participants[0].totalDamageDealt”
Results Query in Laketool running on EC2 took 49.218s to retrieve full data. On the side of the DynamoDB query was executing for 7 min 47.703s which is almost 10 times slower but then it fails with error:
SELECT failed. ProvisionedThroughputExceededException. H2UR3BJP0C3O0UCK8RADAU94GVVV4KQNSO5AEMVJF66Q9ASUAAJG. The level of configured provisioned throughput for the table was exceeded. Consider increasing your provisioning level with the UpdateTable API. Terminated
Which suggests that for this amount of data, DynamoDB’s data throughput is too low (in base free version) and it can’t execute the query, returning the full data.
Conclusions Based on the test performed, it can be seen that Laketool running under the conditions of a weak free VM instance on the AWS platform, performs much better at the task of extracting data from JSON files than DynamoDB in the free version. Especially because Laketool doesn’t require the costly (in terms of time) and problematic process of migrating data from a file store to a database like DynamoDB does, but instead can run on uploaded files right away. Without the need for actually any configuration, other than pointing to the path of the data lake.